Designing for the Brain Under Pressure: AI-Powered Training for HR’s First Response
An OMO learning system that makes steadiness trainable and measurable—so HR can hold nuance when emotion is high and facts are incomplete
A Room That Learned to Whisper
One of my old managers once screamed at the entire room because she couldn’t find her camera.
No one challenged it. Not in the moment. Not after. The room simply became silent—except it didn’t, not really. Something shifted. I remember my shoulders lifting without my choosing. I kept my eyes on my notebook as if looking busy could make me invisible. The air felt thinner. Nobody moved.
In the months that followed, the room became a sensor. We learned to scan her mood before speaking. We learned to time our questions. We learned to keep our suggestions small. The fear wasn’t dramatic. It was ambient—like a low hum under everything.
That’s what happens when nobody knows how to respond to emotional dysregulation: the behavior doesn’t stop. It just trains everyone around it to shrink.
So here’s the real question. If someone had gone to HR that day and said, “I don’t feel safe bringing up problems anymore,” what should HR have said back?
That question is where this system begins.
The Gap Between Knowing and Doing
Most HRBPs know what “good” looks like in theory. They can describe empathy. They can explain neutrality. They can list boundaries, escalation paths, and policy constraints.
And still, the first response often goes wrong. By “first response,” I mean the very first written reply HR sends after an employee raises a concern—often in WeChat or Slack—before the facts are clear.
On paper, that reply is simple. In reality, it’s one of the highest-cognitive-load sentences HR writes.
Not because the HRBPs don’t care. Because the moment is fast, messy, emotionally loaded, and usually happens in writing. HRBPs are trying to do several things at once: acknowledge distress without confirming facts they haven’t verified; remain neutral without sounding cold; set expectations without overpromising; ask a clarifying question without sounding accusatory—all in under five minutes while everything else keeps moving.
So the failure mode isn’t ignorance. It’s overload.
I felt that overload the first time I tried to simulate the moment myself. When I ran first-response scenarios with ChatGPT, I watched my own language swing under pressure. A message arrives. The cursor blinks. My first impulse is either to soothe too quickly (“I’m so sorry, that’s unacceptable”) or to hide behind procedure (“Please provide details per policy”). Then comes the overcorrection: delete, rewrite, delete again. What looks like “word choice” is often a nervous system trying to stabilize itself while holding contradictory constraints.
This is why “do the right thing” isn’t a reliable instruction. Under stress, the brain’s capacity for nuance narrows; people default to simpler, safer-seeming moves—either over-joining (too aligned) or detaching (too procedural). Organizational research describes this pattern as “threat-rigidity”: when threat rises, responses become more constrained and less flexible.
Once you see that, the design requirement becomes obvious: the solution can’t be “try harder” or “be more empathetic.” The solution has to be practice designed for the brain state the work actually happens in—so steadiness becomes something trainable, not something you have to summon perfectly in real time.
A Small System for a High-Stakes Minute
This essay is also a deliverable—and it describes a design in progress, not a finished implementation.
What I’m designing is an AI-powered practice system for the first HRBP response: the moment that often decides whether trust stabilizes or collapses. The use case is as ordinary as it is high-stakes: an employee messages HR about a manager conflict, usually over WeChat or Slack, with emotion running high and facts still incomplete. The system is meant to be simple enough to run, but structured enough to change behavior.
In this design, “steadiness” isn’t treated as a personality trait. It’s treated as a developable capacity—one that becomes measurable through specific first-response skills: acknowledgment, neutrality, boundaries, and a clarifying question. The work isn’t “be calm.” The work is: can the first reply hold steadiness and structure at the same time?
The delivery logic is OMO: online practice stitched to offline calibration and on-the-job reinforcement, so learning doesn’t stay trapped inside training.
At a high level, the design begins with calibration: an offline workshop where “good” becomes a shared standard rather than a personal vibe. Then it moves into five days of short daily practice—ten minutes a day—powered by AI roleplay and rubric-based feedback. Finally, practice is linked to real work through a structured case note template, so the skill transfers into the workflow rather than staying in training.
AI doesn’t replace judgment here. I use it for what humans can’t do at scale: simulate realistic scenarios repeatedly, score responses against consistent criteria, and give immediate feedback while the moment is still alive.
One-Page Spec
For HR readers who want the design in one view, here’s the one-pager before the story of how it came together.
Purpose
Train HRBPs to deliver a first reply that restores steadiness, protects neutrality, and moves the case toward facts—fast and consistently.
Use case
The first written HR response to an employee message about a manager–employee conflict (WeChat/Slack), when emotion is high and facts are incomplete.
Success standard (Rubric, 0–3 each)
Acknowledgment — names impact + thanks them; no unverified facts
Neutrality — no judgment/siding; “understand first” framing
Structure + Boundaries — clear next step + realistic confidentiality + no promises
Clarifying Question — one gentle ask for a concrete example (what/when/where/witness)
Pilot target
Average score improves ~1.5 → ≥2.5 after 3 practice rounds.
Risk-aware scoring
Fail-fast triggers: siding/judgment; promising remedies; stating wrongdoing as fact
Coaching tags: weak question; cold tone; vague next step
OMO flow
Offline (90 min): calibration with contrasting examples + coached rewrites
Online (5 days): 10 min/day AI roleplay → score → rewrite → re-score
Workplace transfer: structured case note (summary, timeline, behaviors, risk flags, next steps)
Guardrails
Periodic facilitator reliability checks + occasional AI–human calibration to prevent scoring drift.
The 60-Second Test
I didn’t arrive at this system by imagining an ideal learner. I arrived at it by trying to write the first response myself.
I set a timer for sixty seconds and imagined the message I dread receiving: “I don’t feel safe bringing up problems anymore.” Then I tried to write back.
I felt an inner tug-of-war immediately: one part of me wanted to reassure too fast, to sound warm enough that the person wouldn’t disappear. Another part of me wanted to protect the case, to avoid committing anything unsafe before I had facts. The timer was running, and the cursor was blinking like a metronome. My drafts started swinging—too aligned, then too procedural—like a pendulum trying to find the center.
That “felt sense” of wrongness mattered. It told me the skill wasn’t knowledge. It was constraint-holding under time pressure.
So I asked ChatGPT to coach me. I showed my drafts to it and asked what structure I was missing. It gave me a language for what I was doing intuitively but inconsistently: a set of criteria that made the invisible visible.
Training That Survives Friday at 4:47 PM
Many corporate training fails at behavior change not because learners are unmotivated, but because the learning environment doesn’t resemble the performance environment.
HR training often happens in a conference room: slides, calm voices, time. Real HR moments happen in a message thread late in the day, when we’re depleted, when emotions are high, and when ambiguity is everywhere.
This is what that looks like. It’s Friday 4:47 PM. The HRBP has already had too many meetings, and their brain is running on whatever’s left. A message appears: “I can’t take this anymore.” The first impulse is to type something quick—not from indifference, but from the body’s need to reduce tension. Then they reread it and immediately feel the problem: it’s either too vague to help or too specific to be safe. They soften it, and the structure disappears. They add structure back, then the warmth drains out. That back-and-forth is the skill gap.
From a neuroscience perspective, this is predictable. Under stress, the systems that support executive control and nuance are more likely to get compromised, and people lean toward simpler, more automatic responses.
So practice has to look like performance: short time windows, realistic chat language, believable emotional intensity, and the exact kinds of ambiguity that trigger collapse. If practice stays calm, learning happens in a brain state that won’t exist when the skill is needed—and reconstruction of the knowdge and skill building suffers. (Reconstruction is not automatic; it depends heavily on context and conditions.)
The goal isn’t comfort. The goal is steadiness under discomfort.
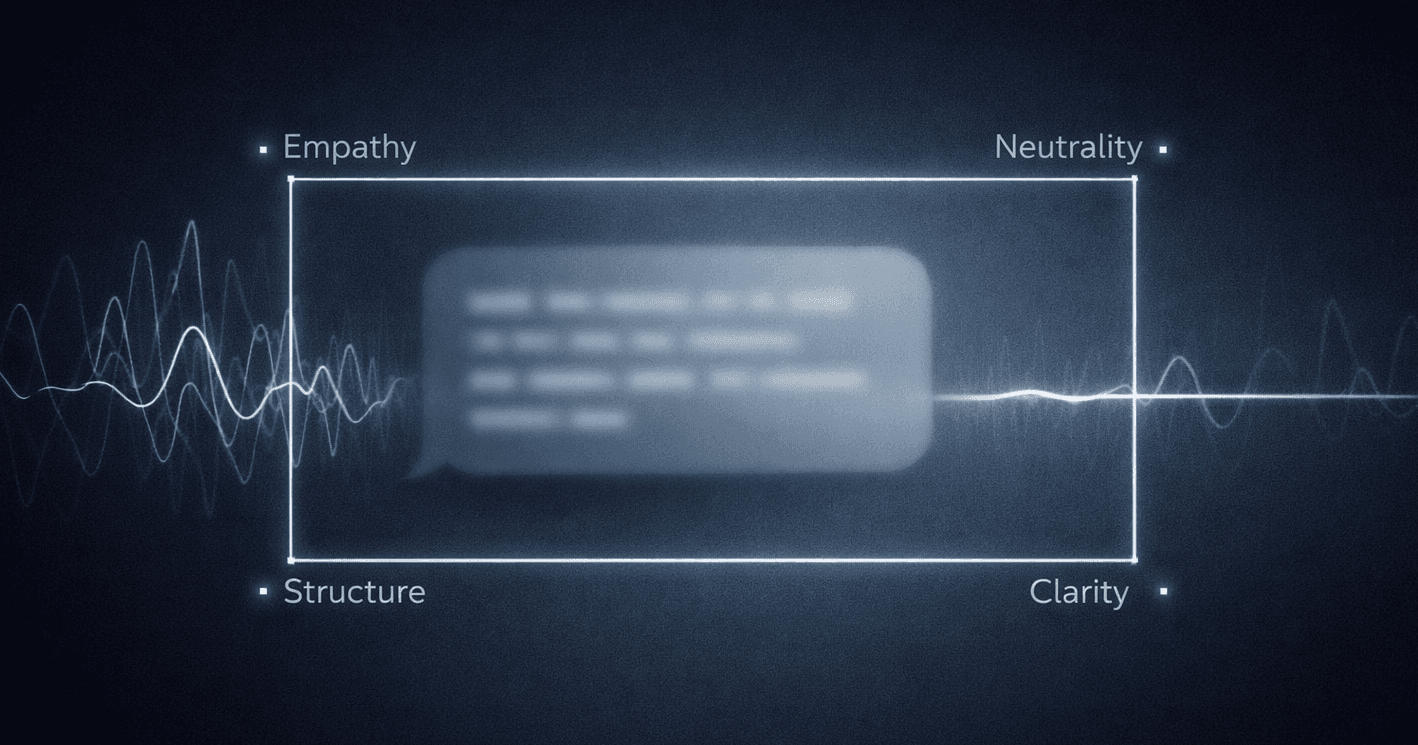
A Rubric That Fits in the Brain
When I first asked ChatGPT to critique my drafts, it proposed six criteria: empathy, neutrality, structure, clarifying questions, confidentiality/boundaries, and tone.
The logic was right, but six is too much for the moment we’re training. Under stress, working memory shrinks; people don’t execute comprehensive frameworks—they execute what they can hold. This is consistent with Nelson Cowan’s working-memory synthesis, which argues a central limit closer to a handful of meaningful items—often summarized as ~4; in Cowan’s words, the limit can “result in the apprehension of roughly 4 chunks of information.”
So the rubric was compressed into four criteria by design. “Structure” and “boundaries” were merged (they serve the same function: reducing uncertainty without overcommitting), and “tone” was folded into empathy and neutrality (tone is how those qualities are expressed, not a separate ingredient).
That leaves four criteria that can actually be carried into a live moment—empathy/acknowledgment, neutrality, structure + boundaries, and a clarifying question.
The Anatomy of a Safe First Reply
Here are the four criteria that define “good” in this system. They stay deliberately small because in the real moment, attention is limited—and the standard has to be runnable.
- Empathy/Acknowledgment
A high-quality reply acknowledges impact and thanks the employee for sharing—without confirming facts we haven’t verified.
- Neutrality
A high-quality reply avoids judgment and loaded assumptions, and frames the conversation as “understanding what happened” before taking action.
- Structure + boundaries
A high-quality reply offers a clear next step (usually a brief call), sets realistic expectations for confidentiality, and avoids promising outcomes.
- Clarifying question quality
A high-quality reply asks for one concrete example gently—what was said or done, when and where, and whether anyone else was present.
A second layer matters in real HR work: mistakes are not equal. A weak clarifying question can be repaired. But language that takes sides—or promises a remedy—can compromise process integrity immediately. That’s why scoring isn’t only “add up four numbers.” It includes failure-mode weighting.
High-risk triggers (heavy penalty / “fail fast”):
taking sides / judgmental language
promising outcomes or remedies
stating wrongdoing as fact before verification
And beyond risk, the system also needs signals for learning design iteration—patterns that are coachable and tell the scenario bank what to train next.
Coaching tags (tracked for iteration):
weak clarifying question (doesn’t move toward specifics)
cold tone / no acknowledgment
vague next step / missing structure
This is how a reply can sound warm and organized and still be unsafe—and how the system stays clear about the difference.
Where the Rubric Stops Being a Document
The hardest part isn’t writing the rubric. It’s designing a process where a room of HRBPs can agree on what “good” looks like—especially the line between empathetic and too aligned, between neutral and detached.
So the workshop isn’t designed to begin with a slide of definitions. It begins with calibration through contrast: two first replies placed side by side—one that feels warm but quietly increases risk, and another that feels safe but lands cold.
In the design, the first ten minutes are intentionally uncomfortable. Someone will usually say, “I’d rather receive the warm one,” and someone else will counter, “I wouldn’t want that on record.” That tension is the point. The task is to name what each reply protects, what each sacrifices, and what minimal edits would allow both humanity and operational integrity to hold in the same message.
That discomfort isn’t a side effect. It’s the cognitive work the job demands: holding competing constraints without collapsing into one extreme.
How the System Learns Us Back
Rubric scores show performance. Tags show pattern—and that’s where the work shifts from judgment to design.
In an initial rollout, the expectation is straightforward: scores should rise meaningfully across rounds—roughly from 1.5 to 2.5 after three cycles—because the loop is built for visible improvement, not vague reflection.
That’s also why tagging matters. It isn’t surveillance. It’s diagnoses at scale. When the same failure shows up again and again, it’s not treated as a character flaw; it’s treated as information. It tells us which conditions reliably break steadiness, which prompts the need for refinement, and which micro-language the feedback should teach more explicitly.
Over time, the scenario bank becomes less like “content” and more like a map of human predictability under stress—plus a method for training steadiness back into place.
OMO Journey
This is designed as an OMO journey because one format alone doesn’t hold the whole skill.
The first stage is offline calibration: ninety minutes, focused and practical. The goal is alignment—what the skill protects (employee trust, evidence quality, case integrity, business stability) and what “good” actually sounds like when the room is tense. The design uses group scoring of sample replies to anchor standards, followed by short role-plays with coached rewrites, so learners leave with both a shared rubric and usable language.
The second stage is the online practice loop: ten minutes a day for five days, powered by AI roleplay and rubric feedback. Each drill presents an employee message. The learner writes a first reply. AI scores it against the rubric, assigns tags, and gives one targeted rewrite instruction. The learner revises and resubmits. The drill ends with a cleaner attempt and a clearer sense of what changed and why.
The third stage is workplace reinforcement. Practice is only useful if it attaches to real work. So the journey includes one concrete on-the-job output: a structured case note—an internal record that captures what was reported, when it happened, how it impacted the employee, any immediate risk flags, and the next steps and owners, written in neutral, auditable language. It isn’t paperwork for its own sake—it’s a way of protecting fairness, clarity, and operational integrity when multiple stakeholders are involved.
Then comes the fourth stage most programs leave to hope: reconstruction. The gap is rarely learning—it’s reconstruction under real conditions. So thirty days later, the design includes a lightweight reconstruction check: a small sample of real first replies (anonymized) is blind-scored against the same rubric to see whether the skill is being rebuilt inside real work—under time pressure, ambiguity, and emotion—or whether it stayed trapped in the calm conditions where it was learned.
Privacy note: all practice scenarios are synthetic, and any real-message sampling for transfer would be anonymized and governed by strict access controls.
The Moment of Truth, Simulated
Input Artifact (Employee Chat message)
I want to discuss something with you. My manager has been under a lot of stress recently and often takes it out on me.
He has spoken to me very harshly in group chats and criticized me in front of others. Sometimes he also sends me private messages with really hurtful words.
I've been feeling anxious every day at work and I'm not sleeping well.
I don't want to make a big deal out of this, but I'm not sure what to do.
Gold-Standard HRBP Reply
I’m sorry you’re dealing with this, and thank you for reaching out.
If you’re open to it, can we do a quick 15-minute chat today so I can understand what happened and support you appropriately? And to help us start, could you share one recent example (what was said or done, when/where it happened, and whether anyone else was present)?
I’ll keep this as confidential as possible and share only on a need-to-know basis; if there are serious safety or compliance concerns, I may need to escalate per process, but I’ll keep the circle tight and align with you before any next steps.
This reply doesn’t solve the situation. It restores steadiness—just enough to make the next step possible.
What This Produces
In this AI HR role-play system, the design runs on a scenario database—a library of synthetic employee messages meant to simulate the first-response moments HRBPs face in real work.
Scalability here isn’t about writing one good scenario. It’s about building a scenario library that’s large and varied enough to prevent memorization and force generalization.
In a real deployment, the database usually grows to 30–50 scenarios—not as a random pile, but as deliberate variations of core patterns. Emotional intensity is only one axis. The scenarios also need to vary by ambiguity, risk flags, and social complexity.
Examples of scenario variations that matter (because they break steadiness in different ways):
The employee uses vague language (“he’s just toxic”), and we have to pull it toward specifics
The employee asks for anonymity up front (confidentiality boundaries become the center)
The employee references protected characteristics or discriminatory language (protocol shifts immediately)
The manager is high-performing or widely liked (neutrality becomes harder, not easier)
The employee oscillates—minimizing the issue, then escalating it (structure needs to hold)
The system doesn’t start at 50. It starts calibrated and expandable. Once the rubric and rewrite loop are stable, new scenarios become multiplication rather than reinvention: templated variations guided by observed failure patterns.
As the library grows, guardrails are needed to prevent drift. If two facilitators score the same reply differently, the system loses trust. Periodic inter-rater reliability checks—paired with occasional AI–human calibration sessions—help compare judgments, refine scoring anchors, and keep “good” stable over time.
In other words, scale isn’t just more content. It’s quality control.
What This Reveals About High-Stakes Communication
This design started with HR, but it doesn’t belong to HR alone.
The pattern underneath is wider: emotional activation plus ambiguity pushes people into simpler, more rigid responses. The organizational version of this is threat-rigidity—when threat rises, flexibility drops, and people narrow to a smaller set of options. The neurological version is similar: stress can impair the brain functions that support nuance and inhibition, making it harder to hold multiple constraints at once.
That combination—high stakes, incomplete facts, human distress—is not unique to HR. It shows up in medicine (patient fear + clinical accuracy + family dynamics + protocol), teaching (upset student + classroom stability + parent pressure + policy), customer support (angry customer + company limits + metrics + empathy), and management itself (performance conversations under time pressure).
Across these fields, the failure mode is predictable. Communication collapses into binary moves: soothe too quickly or retreat into procedure; over-align or detach; be “human” or be “safe.” The tragedy is that the work actually requires both.
What changes from profession to profession are the specifics: the rubric language, the scenario library, the compliance boundaries. What stays constant is the learning problem: scripts don’t transfer under pressure unless practice is built to recreate the conditions of performance.
That’s the thought I keep coming back to: steadiness isn’t something some people magically have and others don’t. It’s a capacity that can be trained—if training respects how the brain behaves under load. This HR system is one implementation of that principle. The method is transferable.
Closing Thoughts: Structure as a Form of Steadiness
When someone reaches out in distress, what they’re really asking is not whether HR has a policy. They’re asking whether the organization can hold them without making them smaller. The first response doesn’t resolve the case. It sets the physics of the next hour: whether the employee stays present or shuts down, whether facts can surface or collapse into fear, whether the process begins with trust or with damage control.
This is why the first reply is never just “soft.” It’s operational. A few sentences can shape the quality of documentation, the direction of escalation, the contours of risk, and—sometimes—the employee’s willingness to stay.
Most workplaces don’t fail because they lack policies. They fail because, in the moment, nobody can hold steadiness and structure at the same time. Under pressure the mind goes blank, reaches for the wrong script, or protects itself by becoming procedural. That’s not a moral failure. It’s a cognitive reality.
That’s what this design is for: to treat steadiness as a developable capacity, make it measurable through first-response skills, and train it in the same conditions it’s needed—so it becomes repeatable rather than heroic. Available on an ordinary Tuesday, when the message arrives and the room starts to tilt.
About the Author
Hi, I'm Zoe. I am a Learning Experience Designer and Behavioral Strategist working at the intersection of learning science, psychology, and human-centered AI product design—with a focus on designing interfaces and experiences that don’t just produce output, but foster self-understanding and durable skill-building. If your team is building AI tools for learning or behavior change and you value both rigor and care, I’m open to conversations about Learning Experience Design, Behavioral Design, and Human-Centered AI product roles.